
Imagine you’re trying to solve a complex problem or analyze vast amounts of data efficiently. How do you store and organize this information in a way that enables faster and more effective computations?
This is where data structures come into play. They enable developers to organize, store, and manipulate data in the most efficient way possible. By understanding and utilizing the right data structures, you can revolutionize your code and enhance the performance of your programs.
What are data structures?
Just like you use folders to keep your schoolwork organized, data structures help you keep your code organized and efficient.
Data structures can be thought of as the building blocks of computer programs. They provide a systematic way to store and organize data, allowing for efficient access, manipulation, and retrieval.
Data structures are designed to optimize the use of memory and execution time, making them vital for achieving high-performance programming.
Check Out!
Data structures also play a significant role in object-oriented programming (OOP) by providing a foundation for organizing and managing data within classes and objects.
Check out the top 9 object-oriented programming that every developer should get familiar with.
Why are data structures important?
Data structures play a pivotal role in programming for several reasons.
Data structures allow us to store and organize data in a way that optimizes access and retrieval. By choosing the appropriate data structure, we can reduce the time and resources required to perform operations on the data.
Data structures provide operations to manipulate and modify data. They offer methods for adding, removing, updating, and searching for data elements, enabling us to perform complex operations on the data efficiently.
Data structures are closely linked to algorithms. Different data structures are suitable for solving different types of problems. By understanding the characteristics and properties of various data structures, we can design algorithms that efficiently solve specific problems.
Data structures help in managing memory effectively. They allocate memory dynamically based on the requirements of the data, optimizing memory usage and preventing wastage.
Using appropriate data structures promotes clean and organized code. It helps in separating the data from the logic, making the code modular and reusable. This improves code readability, maintainability, and overall software quality.
Choosing the right data structure can significantly impact the efficiency of algorithms and operations performed on the data. By selecting an efficient data structure, we can improve the performance of our programs, reduce time complexity, and solve problems more effectively.
How can data structures revolutionize code?
Choosing the right data structure can totally change the way your code performs. By selecting the right data structure for a specific task, you can optimize memory usage, reduce processing time, and enhance the overall performance of your program.
Let’s explore 5 essential data structures that can revolutionize your code!
1. Array
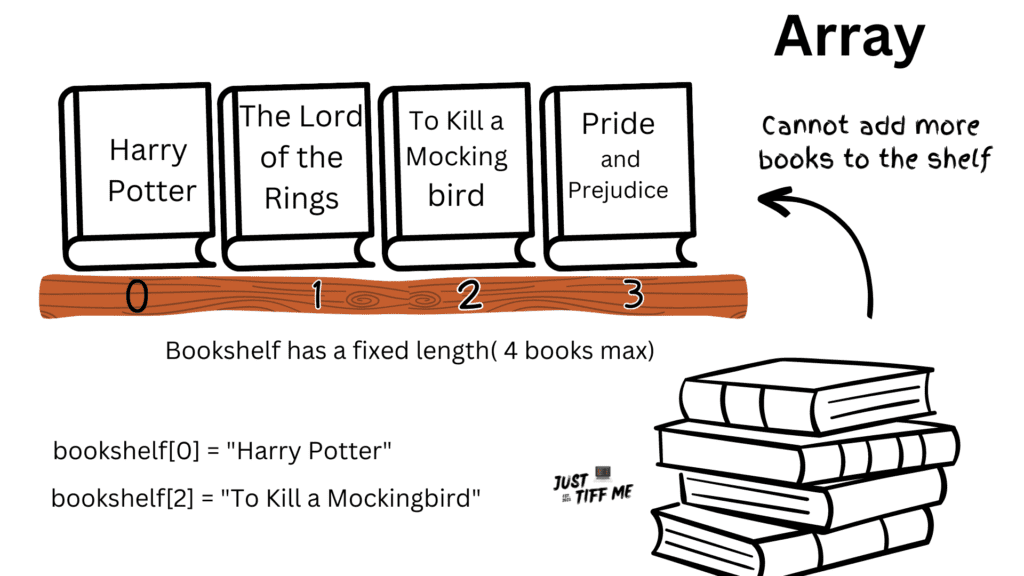
Arrays are the simplest and most fundamental data structure. It is a collection of elements of the same type that are stored in contiguous memory locations.
In simpler terms, an array is a way to store a group of related values or data items together.
Each element is assigned a unique index, starting from 0.
How does an array work?
Arrays work by allocating a contiguous block of memory to store the elements.
Each element in the array has a unique position called an index, starting from 0 for the first element, 1 for the second element, and so on.
By using the index, we can retrieve, modify, or perform operations on specific elements within the array.
Arrays have a fixed size, meaning that once created, the number of elements it can hold remains constant. This allows for efficient memory allocation and direct access to elements using their indices.
However, it also means that the size of the array needs to be determined in advance.
Example
Example
Imagine you have a box with compartments, and you want to store some items in it. An array is like that box, but instead of compartments, it has slots where you can put things.
For example, let’s say you want to store a collection of your favorite books. You can use an array to hold the titles of those books. Each slot in the array represents a position where a book title can be stored.
Here’s a coding demonstration in Python:
# Creating an array to store book titles
books = ["Harry Potter", "The Lord of the Rings", "To Kill a Mockingbird", "Pride and Prejudice"]
# Accessing a book title from the array
print(books[0]) # Output: Harry Potter
# Changing a book title in the array
books[1] = "The Hobbit"
# Adding a new book title to the array
books.append("The Great Gatsby")
# Removing a book title from the array
books.remove("To Kill a Mockingbird")
# Printing all the book titles in the array
for book in books:
print(book)
In this example, the array named “books” is used to store the titles of favorite books.
We can access a specific book title by using its position in the array (like the slot number in the box). We can also modify, add, and remove book titles as needed.
So, an array is like a container with numbered slots, and each slot can hold a value.
We use arrays to store collections of related data items, such as a list of numbers, names, or any other kind of information. It allows us to organize and work with multiple values efficiently in our programs.
Type of Array
Now, let’s explore two types of arrays!
One-Dimensional Arrays
Multidimensional Arrays
One-Dimensional Arrays
One-dimensional arrays, often referred to as vectors, are a linear arrangement of elements. They are like a straight line of boxes.
They are ideal for scenarios where data needs to be accessed sequentially or randomly using an index.
Multidimensional Arrays
Multidimensional arrays extend the concept of one-dimensional arrays by allowing multiple indices. They enable efficient storage and retrieval of structured data.
It’s like a table with rows and columns, just like a chessboard. You can use a multidimensional array to store data that has multiple dimensions, like a spreadsheet or an image.
Pros and cons of using arrays
Using arrays as a way to store and organize data has its advantages and disadvantages. Let’s take a closer look:
Advantages
Disadvantages
Advantages
Arrays provide fast and direct access to elements using their index. Since the index represents the position of an element, retrieving or modifying an element at a specific index is efficient.
Arrays store elements in a contiguous block of memory, which allows for efficient memory management and cache utilization. This sequential storage ensures that elements are stored next to each other, making it easier to traverse the array.
Arrays are straightforward to understand and use. We can perform basic operations such as adding, removing, and modifying elements in the array without much complexity.
Accessing elements in an array using an index takes a consistent amount of time, regardless of the size of the array. It’s like finding a specific page in a book using the page number.
Disadvantages
Arrays have a predetermined size that we need to specify when creating them. It’s like having a box that can only hold a certain number of items. If we need more space, we have to get a bigger box.
This can be a limitation when the size of the data is dynamic or unknown in advance.
Adding or removing elements in the middle of an array requires shifting the other elements, which can be time-consuming. It’s like rearranging a row of books on a shelf whenever we want to insert or remove a book in the middle.
If an array has a larger size than the number of elements it holds, some memory space goes unused. It’s like having empty book slots on a shelf, taking up unnecessary space.
Arrays cannot easily change their size once created. If we need more elements than the initial size, we have to create a new array with a larger size and copy the existing elements.
It’s like getting a new, bigger bookshelf and transferring all the books from the old one.
Arrays offer basic functionality and do not provide built-in methods for complex operations like sorting or searching. Additional algorithms or data structures may be required to perform these tasks efficiently.
2. Linked Lists
A linked list is a dynamic data structure that consists of a sequence of nodes. Each node holds information and a pointer to the subsequent node in the list.
Unlike arrays, linked lists do not require contiguous memory allocation, allowing for flexible resizing.
Example
It’s like a train where each carriage is connected to the next one. Linked lists are flexible because we can add or remove boxes easily without worrying about fixed sizes.
How Does Linked List Work?
Imagine you have a set of cards that you want to arrange in a particular order.
Instead of keeping them all together in a stack, you decide to connect them by adding a string or a piece of tape between each pair of cards.
A linked list is a data structure that works in a similar way.
It consists of individual elements called “nodes,” where each node holds some data and has a reference to the next node in the sequence. This way, all the nodes are “linked” together, forming a sequence.
Here’s a simple explanation of linked lists:
Nodes
Connections
Head and Tail
Traversal
Nodes
A linked list is made up of nodes. When you add a new element (or data) to the linked list, a new node is created to hold that data.
Each node holds a piece of data (like a number or a word) and a reference to the next node.
It’s like having a card with information written on it and an arrow pointing to the next card.
class Node:
def __init__(self, data):
self.data = data
self.next = None
# Creating nodes
node1 = Node(5)
node2 = Node(10)
node3 = Node(15)
# Linking nodes
node1.next = node2
node2.next = node3
# Traversing the linked list
current_node = node1
while current_node:
print(current_node.data)
current_node = current_node.next
In this example, we create three nodes and link them together. We then traverse the linked list starting from the head (node1) and print the data of each node until we reach the end.
Connections
To add the node to the linked list, you need to link it with the previous node. The previous node’s reference now points to the new node, connecting them in the sequence.
The references between nodes create the “link” in linked list.
It’s like the strings or tape that connect the cards together in our example.
Head and Tail
The starting point of the linked list is called the “head.” It represents the first node in the sequence.
The last node in the linked list is called the “tail.” It doesn’t have a reference to the next node, indicating the end of the list.
Here’s a simple visual representation of a singly linked list:
Head Tail
↓ ↓
[Data | Next] -> [Data | Next] -> [Data | Next] -> None
Traversal
To access the data in the linked list, you start from the head and follow the references from one node to the next until you reach the end (tail). This process is called traversal.
Here’s a simple visual representation of a linked list with three nodes (A, B, and C):
+----+---+ +----+---+ +----+---+
| 10 | *----->| 20 | *----->| 30 | / |
+----+---+ +----+---+ +----+---+
In this example, 10, 20 and 30 are the data in each node, and the arrow represents the reference pointing to the next node in the list. The last node (C) has a reference that points to nothing, indicating the end of the linked list.
Now, let’s see a simple coding demonstration of a linked list in Python:
# Define the Node class
class Node:
def __init__(self, data):
self.data = data
self.next = None
# Define the Linked List class
class LinkedList:
def __init__(self):
self.head = None
# Method to add a new node at the end
def append(self, data):
new_node = Node(data)
if not self.head:
self.head = new_node
else:
current_node = self.head
while current_node.next:
current_node = current_node.next
current_node.next = new_node
# Method to print the linked list
def display(self):
current_node = self.head
while current_node:
print(current_node.data, end=" -> ")
current_node = current_node.next
print("None")
# Create a linked list and add elements
linked_list = LinkedList()
linked_list.append(10)
linked_list.append(20)
linked_list.append(30)
# Display the linked list: Output will be "10 -> 20 -> 30 -> None"
linked_list.display()
In this example, we define a simple linked list with three nodes containing the data 10, 20, and 30.
When we display the linked list, it will show “10 -> 20 -> 30 -> None,” representing the sequence of nodes, with “None” indicating the end of the list.
Summary
A linked list works by creating nodes that store data and references to the next node. The nodes are linked together, forming a sequence.
This structure allows for efficient insertion and deletion of elements and provides flexibility in managing data dynamically.
Traversal allows us to access and process the data in the linked list, starting from the head and following the references until we reach the end (tail).
Types of linked lists
There are various types of linked lists, including singly linked lists, doubly linked lists, and circular linked lists.
Singly linked lists
Doubly linked lists
Circular linked lists
Singly linked lists
Singly linked lists have nodes that only point to the next node.They excel in scenarios where frequent insertions and deletions occur at the beginning or end of the list.
Imagine you have a group of friends standing in a line, holding hands. Each friend can only hold the hand of the person standing in front of them.
For example, in our group:
Tom -> Jerry -> Susan -> John -> Mike

Here, Tom holds hands with Jerry, Jerry with Susan, Susan with John, and John with Mike. The arrows represent the pointers connecting the nodes.
If we want to find out who is standing after John. we simply ask John who will point to Mike. Mike doesn’t know anyone.
Singly-linked lists are like a one-way street. We can only move forward in the list by following the links from one element to the next. They are simple and efficient in most cases.
Doubly linked lists
Doubly linked lists have nodes that point to both the next and previous nodes. This enables bidirectional traversal and efficient insertion and deletion at any position. Doubly linked lists strike a balance between flexibility and performance.
Now, let’s imagine a slightly different scenario.
Picture the same group of friends standing in a line, but this time, each friend knows the friend standing in front of them and the friend standing behind them. It’s like they’re holding hands with two people.
To make it more relatable, let’s use the same example.
Tom <-> Jerry <-> Susan <-> John <-> Mike

Here, each person holds hands with the person in front and behind. The arrows go in both directions to represent the pointers connecting the nodes.
If we want to findout who is standing after John. we simply ask the John who will point to the Mike. Mike also knows John.
Now, we can move forward and backward in the list easily because each friend knows the one in front and the one behind.
Doubly linked lists offer more flexibility compared to singly linked lists because we can traverse the list in both directions. However, they require extra memory to store the backward links
Circular linked lists
Imagine the same group of friends, but this time, they form a circle by holding hands. Each friend knows the friend standing on their left and the friend on their right. It’s like a human loop. This is called a circular linked list.
For example, in our group:
Tom -> Jerry -> Susan -> John -> Mike -> Tom

Here, Tom holds hands with Jerry, Jerry with Susan, Susan with John, John with Mike, and Mike with Tom, completing the circle
Notice that this time, Mike knows both John and Tom.
Circular linked lists are like a never-ending cycle. They can be useful when we want to repeat a sequence or continuously loop through a set of elements.
Advantages of linked lists
Linked lists offer several advantages:
They can dynamically adjust their size, making them suitable for scenarios where the number of elements is unknown or frequently changing.
Linked lists are great when we don’t know how many items we’ll have or when we want to add or remove items quickly, as elements can be easily rearranged by updating references.
They’re like a flexible chain where we can easily insert or remove links without breaking the chain. So, if you have a list that changes a lot, a linked list is a smart choice.
Linked lists utilize memory efficiently by allocating memory for each node as needed. This avoids the need for a fixed-size allocation like in arrays, where unused memory can be wasted.
Linked lists have a simple structure, making them easy to implement and understand. They consist of nodes with data and references, without the need for complex operations or algorithms.
Disadvantages of linked lists
Linked lists also have some drawbacks.
Finding a specific element in a linked list takes time. It’s like searching for a specific link in a chain. You have to start from the beginning and follow the links one by one until you reach the desired element.
This can be slow if you need to access elements randomly.
Each node in a linked list requires additional memory to store the data and the reference to the next node. This overhead can be significant compared to arrays, which store data consecutively.
Linked lists don’t store elements next to each other in memory. It’s like having scattered links in a chain. This can cause slower performance because accessing non-contiguous memory locations is not cache-friendly.
Traversing a linked list to access or modify elements requires following the references from one node to the next.
This traversal can introduce additional time complexity, especially for operations that involve iterating through the entire list
In a singly linked list (where each node has a reference to the next node), backward traversal is not efficient.
To traverse backward, a doubly linked list (where each node has references to both the previous and next nodes) would be more suitable.
3. Stack
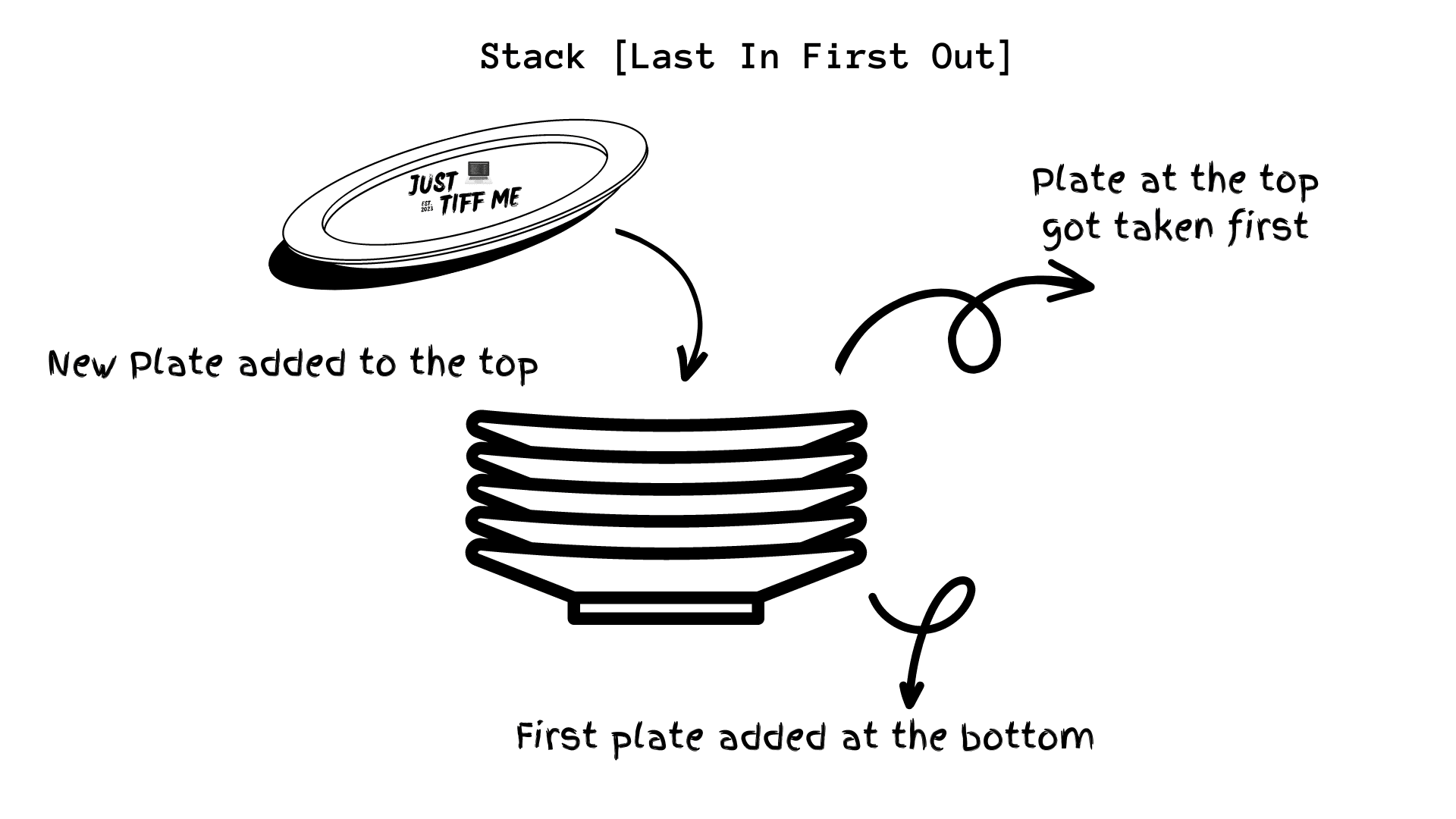
A stack is a data structure that follows the Last-In-First-Out (LIFO) principle.
It resembles a stack of plates, where the last plate added is the first one to be removed. Stacks are commonly used in situations where the order of elements matters, such as function calls, undo operations, and expression evaluation.
LIFO principle
The LIFO principle dictates that the last element added to the stack is the first one to be removed. This property allows for efficient insertion and deletion operations, as they only involve the topmost element of the stack.
When you add something to a stack, it goes on top of the previous item. And when you remove something from a stack, you take the top item first.
It’s like adding books to the top of the pile or taking books from the top.
Applications of stacks
Stacks find applications in various domains, including parsing and evaluating mathematical expressions, backtracking algorithms, and managing function calls in programming languages.
Stacks are useful when you want to keep track of things in a specific order. For example, when you’re writing a text editor and you want to keep track of the undo operations, you can use a stack to remember each action and easily undo them in reverse order.
Advantages of Stack
Imagine you have a stack of pancakes, and you want to remove the topmost pancake. You simply lift off the top pancake without having to move the ones below it.
Below are the advantages of using stack:
Stacks are easy to understand and use. The Last-In-First-Out (LIFO) behavior is straightforward, making it simple to implement and work with a stack.
The fundamental operations of pushing and popping elements from a stack have a constant time complexity of O(1). This makes stack operations highly efficient and ideal for scenarios where fast access to the most recent elements is required.
Stacks are used to manage function calls in programming languages. Each function call is added to the stack, and when a function completes, its execution context is removed from the stack, allowing the program to return to the previous point.
Think of a game where you can undo or redo moves. Each move is added to the stack, and you can easily undo or redo by removing moves from the top of the stack.
Disadvantages of Stack
Imagine you have a stack of plates, and you want to get the plate in the middle. You would need to remove all the plates on top until you reach the desired plate.
If you want to swap the positions of two plates in the middle, you would need to remove all the plates on top until you reach the desired plates and then put them back in the desired order.
Below are the drawbacks of using stack:
In a stack, you can only access the topmost element. If you want to access elements in the middle, you need to remove the elements on top until you reach the desired one.
This can be inefficient if frequent access to non-top elements is required.
Unlike arrays or lists, stacks do not provide random access to elements. You cannot directly access or modify elements in the middle or bottom of the stack. If random access is necessary, a different data structure may be more suitable.
Stacks do not allow rearranging the elements easily. You can only add elements to the top or remove them from the top.
In some programming languages, stacks have a fixed size, and if the stack exceeds its capacity, it can result in a stack overflow error. This limitation can be mitigated by using dynamically resizable stacks or implementing appropriate error handling.
While stacks are useful in specific situations, they may not be the best choice for all scenarios.
For example, if you need to access elements in a different order, such as first-in-first-out (FIFO), a queue data structure would be more appropriate.
4.Queue
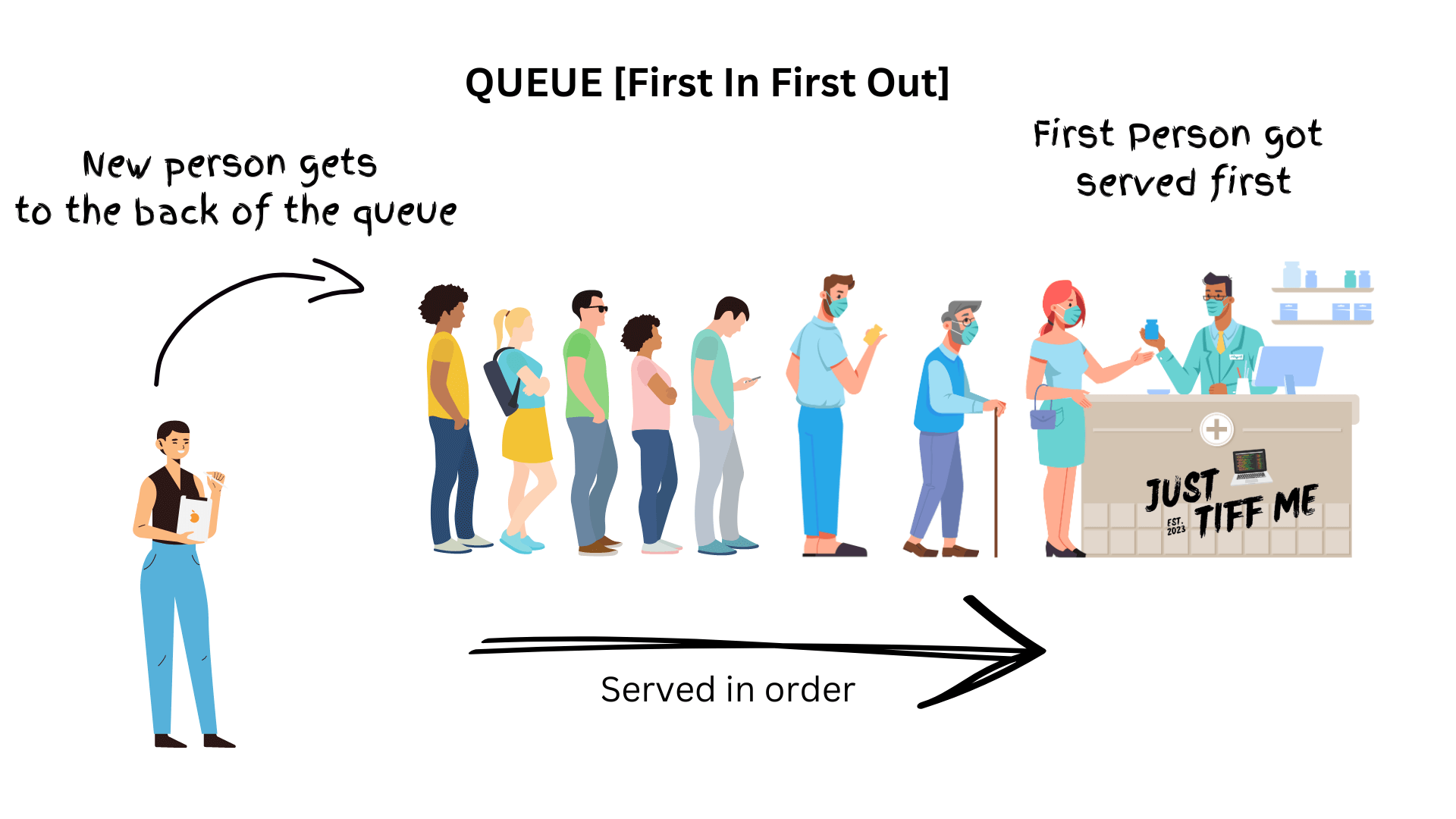
A queue is a data structure that follows the First-In-First-Out (FIFO) principle.
It resembles a queue of people waiting in line, where the first person to arrive is the first one to be served, and new people join the line at the end
Queues are commonly used in scenarios where the order of elements is significant, such as scheduling tasks and managing resources.
FIFO principle
The FIFO principle states that the first element added to the queue is the first one to be removed.
When you add something to a queue, it goes to the end of the line. And when you remove something from a queue, you take the first item in line.
It’s like waiting in line to buy tickets for a movie!
It ensures that elements are processed in the order they were added, making queues suitable for handling tasks that require strict ordering.
Applications of queues
Queues have numerous applications, such as job scheduling, breadth-first search algorithms, and handling requests in web servers. They are great when you have tasks or jobs that need to be processed in order.
For example, when you’re building a print queue for a printer, you want to make sure that print jobs are processed in the order they were received.
They provide an efficient way to manage and process elements based on their arrival time, ensuring fairness and maintaining the desired order of operations.
Advantages of Queue
Queues preserve the order of items, follow a “first-in, first-out” (FIFO) order. If you arrive first in the line, you’ll be served first.
This is important in scenarios where order matters, such as processing tasks in the order they were received
Adding an item to the back of the queue (enqueue) or removing an item from the front of the queue (dequeue) is fast and efficient.
It’s like joining the line or being served next without disturbing the other people in the queue.
Disadvantages of Queue
In a queue, you can only access the element at the front. If you want to access elements in the middle, you need to remove (dequeue) elements from the front until you reach the desired one.
This can be slow if you need frequent access to non-front items
Queues don’t allow you to jump ahead to a specific item. You have to go through the items one by one from the front.
If you need to access items randomly, like the 5th or 10th item, a queue may not be the best choice.
In some cases, queues have a fixed size. If you try to enqueue more items when the queue is full, it’s like trying to join a full line.
This can cause problems, so it’s important to handle such situations properly.
Queues are great for scenarios where maintaining order and fairness is important, such as handling requests or processing tasks in the order they arrive.
However, if you need to access items in a different order, like the last-in-first-out (LIFO) order, you might need a different data structure like a stack.
Tree
A tree is a hierarchical data structure that consists of nodes connected by edges.
It resembles the structure of a real-life tree, with a root node at the top and branches leading to subsequent nodes. Each node can have child nodes, forming a hierarchical structure.
Example
When you’re building a file system, you can use a tree structure to represent folders and files. It helps you quickly find and organize your files.
How Tree works
A tree consists of nodes connected by edges. It is similar to a real-life tree, where the nodes represent elements, and the edges represent the relationships between them.
Here’s how a tree data structure works:
Nodes
Parent and Child Nodes
Hierarchy and Levels
Leaf Nodes
Traversal
Nodes
A tree is made up of nodes. Each node contains a piece of data and can have zero or more child nodes connected to it.
The first node is called the root, and it serves as the starting point of the tree.
Parent and Child Nodes
Nodes in a tree have relationships with other nodes.
A parent node is connected to its child nodes through edges.
Each child node has exactly one parent node, while a parent node can have multiple child nodes.
Hierarchy and Levels
Nodes in a tree are organized in a hierarchical structure.
The root node is at the top level, and the child nodes are below it. Nodes at the same level are called siblings.
Leaf Nodes
Leaf nodes are nodes that do not have any child nodes. They are the endpoints of a tree branch and represent the lowest level of the tree.
Traversal
Traversal refers to the process of visiting and accessing nodes in a tree.
There are different traversal techniques, such as depth-first traversal (pre-order, in-order, and post-order) and breadth-first traversal.
These techniques determine the order in which nodes are visited.
Here’s a simple visual representation of a tree:
# visual representation of a tree
A
/ \
B C
/ \ / \
D E F G
In this example, we have a tree with seven nodes: A, B, C, D, E, F, and G.
- Node A is the root, and it has two child nodes, B and C.
- Node B has two child nodes, D and E, while node C has two child nodes, F and G.
- Node B has two child nodes, D and E, while node C has two child nodes, F and G.
The tree structure is commonly used in various applications like file systems, organizational charts, and decision-making processes.
Using tree data structures, we can perform operations like:
- searching for specific nodes
- inserting new nodes
- deleting nodes
- traversing the tree to access and process the data stored in each node.
Overall, trees provide a flexible and efficient way to represent and work with hierarchical data, making them a fundamental tool in computer science and programming.
Types of trees
There are various types of trees, including binary trees, AVL trees, and B-trees.
Binary trees
AVL Trees
Binary trees
Binary trees consist of nodes that can have at most two children, a left child and a right child.They offer efficient searching, sorting, and traversal operations. Binary trees form the foundation for more advanced tree structures.
Example
Imagine a game where you have to guess a number. At each step, you’re given a hint if the number you guessed is higher or lower than the actual number. A binary tree can represent this guessing game.
Each node represents a guess, and the left child represents a lower number while the right child represents a higher number. By navigating down the tree based on the hints, you can find the correct number efficiently
AVL Trees
AVL trees are self-balancing binary search trees.
It automatically adjust their structure during insertion and deletion operations to maintain optimal balance and improve overall efficiency.
Example
Imagine you have a mechanical book shelf which automatically adjusts its structure when you add or remove any books to keep the books balanced, making it easier to find and organize them. This bookshelf represents An AVL tree.
Advantages of Trees
Trees help organize data in a hierarchical manner. It allows you to represent relationships between elements, such as parent-child relationships.
Trees provide efficient search and retrieval operations. With each step down the tree, you eliminate a large portion of data, making it faster to find the desired information
Depending on the type of tree, such as binary search trees, AVL trees, or red-black trees, these operations can be performed with time complexity better than linear.
This makes trees suitable for scenarios where frequent updates or modifications to the data are required.
Unlike arrays or lists, trees can grow and shrink dynamically as we add or remove nodes. This flexibility makes trees suitable for situations where the size of the data may change over time.
Disadvantages of Trees
Modifying a tree, such as adding or removing nodes, can be complex and require careful restructuring of the tree. This complexity increases as the tree grows larger.
Trees can require additional memory to store the connections between nodes (edges), especially if the tree is unbalanced or has a large number of nodes. This overhead can impact the overall memory usage.
Unlike arrays or lists, trees do not provide direct sequential access to elements.
To traverse a tree, we need to use traversal algorithms like depth-first or breadth-first search, which may require additional time and code complexity.
Certain types of trees, like balanced trees, require careful balancing to maintain their efficiency. Balancing a tree can be a complex task and may introduce additional overhead.
Conclusion
In conclusion, understanding and utilizing the right data structures can have a transformative effect on your code’s efficiency and performance.
Array, linked list, stack, queue, and tree are five essential data structures that can revolutionize your programming. Each data structure has its strengths and weaknesses, and choosing the appropriate one depends on the specific requirements of your program.
By leveraging the power of these data structures, you can optimize memory usage, improve processing speed, and enhance the overall quality of your code.
Learn more about Data Structure
- GeekforGeek: [Data Structures]
- Medium: [8 Common Data Structures every Programmer must know]
- simplilearn : [What is Data Structure: Types, Classifications and Applications]
FAQs
Arrays store a fixed-size sequence of elements in contiguous memory, allowing for constant-time access. Linked lists, on the other hand, consist of nodes with data and references, allowing for dynamic resizing and efficient insertion/deletion operations. Arrays provide direct access based on index, while linked lists require traversing the nodes.
You should use a stack when the Last-In-First-Out (LIFO) ordering is essential. Stacks are suitable for scenarios such as function calls, undo operations, and depth-first search algorithms. Queues, following the First-In-First-Out (FIFO) principle, are better suited for managing resources, scheduling tasks, and breadth-first search algorithms.
Yes, a tree can be empty. An empty tree has no nodes and represents the absence of any data. Trees can have various levels of complexity, ranging from a single root node to thousands or even millions of nodes.
No, different data structures have different performance characteristics. The efficiency of a data structure depends on factors such as the type of operations performed, the size of the data, and the specific requirements of the program. Choosing the right data structure for a particular task is crucial for achieving optimal performance.
To improve your understanding of data structures, you can explore online tutorials, read books or articles on the topic, and practice implementing them in programming exercises. Additionally, solving coding problems that involve data structures can help solidify your knowledge and improve your problem-solving skills.
Data structures provide efficient storage, retrieval, and manipulation of data, leading to faster algorithms and optimal resource utilization.
Absolutely! Combining different data structures can enhance the capabilities and performance of your algorithms, solving complex problems efficiently.
No, data structures are conceptually independent of programming languages. However, different languages may provide built-in implementations or libraries for certain data structures.
Consider the specific requirements and constraints of your problem. Evaluate the time and space complexity of different data structures to identify the best fit for your algorithmic needs.
Yes, you can create custom data structures tailored to your specific requirements. This allows you to optimize for your problem domain and further improve algorithmic efficiency.
The time complexity varies depending on the data structure and operation. Here are the average time complexities for some common operations:
- Array access: O(1)
- Array insertion/deletion (at the end): O(1)
- Linked list access: O(n)
- Linked list insertion/deletion (at the beginning): O(1)
- Stack operations: O(1)
- Queue operations: O(1)
- Tree traversal (in-order, pre-order, post-order): O(n)
- Binary search tree (BST) operations (lookup, insertion, deletion): O(log n) on average (O(n) in the worst case for unbalanced trees)
- Hash table operations: O(1) on average (O(n) in the worst case for collision resolution)
When selecting a data structure, you should consider the specific requirements of your application, such as the type of operations you need to perform, the efficiency requirements, and the expected size of the data. Other factors include the ease of implementation, the memory overhead, and the available libraries or language support for a particular data structure.


